Real-Time Scoring & Model Management 2 - Implementation
This is Part 2 in a series on large-scale real-time scoring and model management - The full series is Part 1, Part 2, and Part 3.
System Architecture
Consider a call center application that allows cross-selling products to a customer based on the customer historical data and information from the current call. The type of offer is conditional on the product category the customer is interested in during the call and the region where the customer lives. For example, a customer in Florida would be more likely to buy beach products than one in New England. As the customer service representative interacts with the customer, the application returns new product recommendations as new information becomes available during the call.
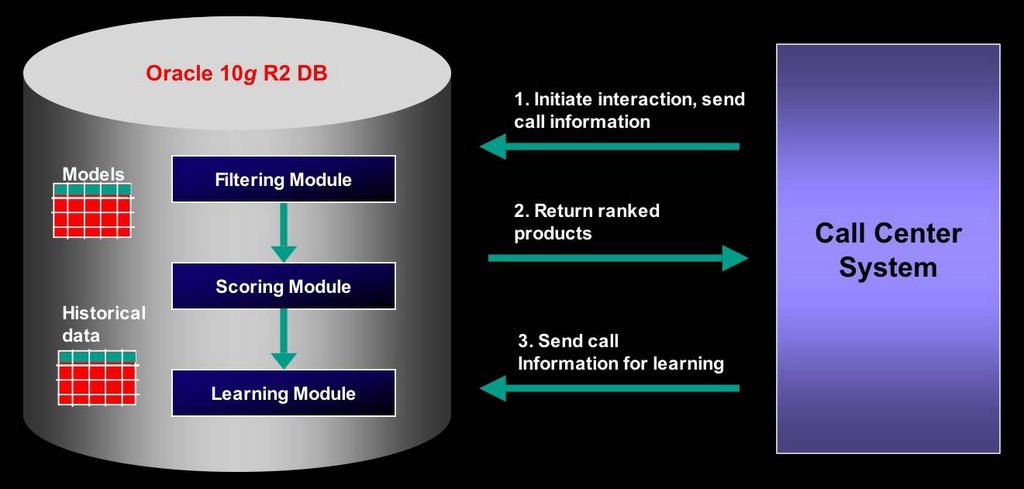
Figure 2: Architecture for a large-scale real-time scoring application.
A simplified architecture for such an application is illustrated in Figure 2. The system has four main components:- Client application
- Filtering module
- Scoring module
- Learning module
- Automated model build
- Champion-challenger testing
- Automated model deployment
- Storage of model metadata
Let's take a look how the Filtering and Scoring modules of the simplified architecture described above can be implemented using the technologies in the 10gR2 Oracle Database. To help illustrate the approach, I am providing implementation examples for each of the steps.
Filtering Module
The Filtering Module selects the set of models appropriated for a given call center call. Filtering is performed on a set of attributes associated with a model – business rules can also be used for defining the filtering criteria. Attributes can be associated with a model in two ways: 1) directly, in the model metadata table, and 2) indirectly, by joining the model metadata table with other tables. Model filtering is accomplished by querying the model metadata table and by applying the desired filtering criteria using a WHERE clause. The filtering criteria can refer to columns from other tables besides the model metadata table.
Consider that we have a model metadata table (modelmd_tab) with the following schema:
model_name VARCHAR2(30),The Learning Module populates this table as models are created and deleted. The information in modelmd_tab identifies the model (name and type), the product and region the model was built for, and the model accuracy. Consider also that we have a product table (products) containing product information with the following schema:
model_type VARCHAR2(30),
prod_id NUMBER,
region VARCHAR2(2),
model_accuracy NUMBER
prod_id NUMBER,The following query selects cross-sell models for the northeast (NE) region:
prod_type VARCHAR2(30),
prod_description VARCHAR2(4000)
SELECT A.model_name, A.prod_idThis approach to model filtering is very flexible. Other types of information can be used for filtering by joining the modelmd_tab table with other tables. For example, we could restrict the models returned by the previous query to those that belong to a given product category (e.g., credit-card) using the following query:
FROM modelmd_tab A
WHERE A.model_type = 'cross-sell' AND A.region = 'NE'
SELECT A.model_name, A.prod_idBy taking advantage of Oracle Spatial and Oracle Text capabilities, this approach can easily accommodate filtering using spatial and textual information.
FROM modelmd_tab A,
(SELECT prod_id
FROM products
WHERE prod_type = 'credit-card') B
WHERE A.model_type = 'cross-sell' AND
A.region = 'NE' AND
A.prod_id = B.prod_id
Scoring Module
This module scores the set of models selected by the Filtering Module using historical customer data and/or call information. In our example, it returns a ranked list of products. The implementation proposed here takes advantage of temporary session tables and model caching for performance.
A temporary session table is used for holding the scoring results for a given request from the client. Before scoring each new request the table is truncated.
For reasonably sized models, caching is achieved through shared cursors. In order to avoid reloading the model every time, this requires the same SQL string to be used for all queries that score a given model. For example, running the following scoring query multiple times would not reload the model tree-model after the first time:
SELECT PREDICTION(tree_model USING A.*)However, if we modify the above SQL string in any way the model would be re-loaded. By using binding variables in the scoring query, it is possible to the get the benefit of caching without sacrificing flexibility:
FROM customers A
WHERE A.cust_id = '1001'
SELECT PREDICTION(tree_model USING A.*)Another benefit of model caching is a reduction in shared pool memory usage, enabling greater concurrency and larger multi-user loads.
FROM customers A
WHERE A.cust_id = :1
In order to implement the Scoring Module, I first created a temporary session table to hold the results. This is done at the time the system is setup. For this example, the table was created as follow:
CREATE GLOBAL TEMPORARY TABLE scoretab(For each score request, scoretab will store a row per each eligible model selected by the Filtering Module. Each row has the ID of the product associated with the model and the probability of the customer buying that product.
prod_id NUMBER,
prob NUMBER) ON COMMIT PRESERVE ROWS;
Next, I created a PL/SQL stored procedure that filters and then scores all the eligible models. For simplicity, I decided to bundle the filtering and scoring modules in a single PL/SQL procedure:
CREATE OR REPLACE PROCEDURE score_multimodel(The score_multimodel procedure takes as inputs the customer ID, for retrieval of historical data, the model metadata name, the temporary session table name, for persisting results, a WHERE clause for product filtering, and a WHERE clause for model filtering. The procedure scores all models associated with the products filtered by the WHERE clauses. Models are scored one at a time and results persisted to the temporary session table. Scoring each model separately and using binding variables allow for model caching through shared cursors.
p_cid NUMBER,
p_model_table_name VARCHAR2,
p_score_table_name VARCHAR2,
p_prod_where_clause VARCHAR2,
p_mod_where_clause VARCHAR2) AS
TYPE Char_Tab IS TABLE OF VARCHAR2(30);
TYPE Num_Tab IS TABLE OF NUMBER;
TYPE ModelCursorType IS REF CURSOR;
v_model_tab Char_Tab;
v_prod_tab Num_Tab;
v_cursor_model ModelCursorType;
v_mod_where VARCHAR(4000) := p_mod_where_clause;
v_prod_where VARCHAR(4000) := p_prod_where_clause;
v_gender CHAR(1);
v_year NUMBER;
v_marital VARCHAR2(20);
v_credit NUMBER;
v_sql_stmt0 VARCHAR2(4000);
v_sql_stmt VARCHAR2(4000);
v_num_models NUMBER;
BEGIN
-- Clear result table
v_sql_stmt := 'TRUNCATE TABLE ' || p_score_table_name;
execute immediate v_sql_stmt;
-- Get customer information (NOTE: this assumes a fixed schema)
SELECT CUST_GENDER, CUST_YEAR_OF_BIRTH, CUST_MARITAL_STATUS,
CUST_CREDIT_LIMIT
INTO v_gender, v_year, v_marital, v_credit
FROM customers WHERE cust_id = p_cid;
-- Open cursor and bulk read to get eligible models
v_sql_stmt0 := 'SELECT prod_id FROM products ';
IF length(v_prod_where) > 0 THEN
v_sql_stmt0 := v_sql_stmt0 || ' WHERE ' || v_prod_where;
END IF;
v_sql_stmt := 'SELECT A.model_name, A.prod_id ' ||
'FROM ' || p_model_table_name || ' A,' ||
'(' || v_sql_stmt0 || ') B ' ||
'WHERE A.prod_id = B.prod_id ';
IF length(v_mod_where) > 0 THEN
v_sql_stmt := v_sql_stmt || ' AND ' || v_mod_where;
END IF;
OPEN v_cursor_model FOR v_sql_stmt;
LOOP
FETCH v_cursor_model BULK COLLECT INTO v_model_tab, v_prod_tab;
EXIT WHEN v_cursor_model%NOTFOUND;
END LOOP;
CLOSE v_cursor_model;
-- Score each model and persist results to temporary table
v_num_models := v_model_tab.count;
FOR i IN 1..v_num_models LOOP
v_sql_stmt :=
'INSERT INTO ' || p_score_table_name ||
' SELECT :1, prediction_probability('|| v_model_tab(i) ||
' USING :2 as CUST_GENDER, :3 as CUST_YEAR_OF_BIRTH, ' ||
' :4 as CUST_MARITAL_STATUS, :5 as CUST_CREDIT_LIMIT) '||
' FROM dual ' ||
' WHERE prediction(' || v_model_tab(i) ||
' USING :6 as CUST_GENDER, :7 as CUST_YEAR_OF_BIRTH, ' ||
' :8 as CUST_MARITAL_STATUS, :9 as CUST_CREDIT_LIMIT)=1';
EXECUTE IMMEDIATE v_sql_stmt USING v_prod_tab(i),
v_gender, v_year, v_marital, v_credit,
v_gender, v_year, v_marital, v_credit;
END LOOP;
END score_multimodel;
/
show errors;
COMMIT;
Consider a product with prod_id = 120, an example of the scoring query in the inner loop of the procedure is as follow:
SELECT 120,This scoring query only returns rows for products that the customer is likely to buy. The outcomes a model can predict are a function of the data provided to the model during training. For this example, a model predicts one of two outcomes: 0, if the customer would not buy the product, and 1, if the customer would buy the product. The use of the PREDICTION operator in the WHERE clause removes, from the result set, products the customer is unlikely to buy.
PREDICTION_PROBABILITY(model1 USING 'M' AS cust_gender,
1960 AS cust_year_of_birth,
'Married' AS cust_marital_status,
50000 AS cust_credit_limit)
FROM dual
WHERE PREDICTION(model1 USING 'M' AS cust_gender,
1960 AS cust_year_of_birth,
'Married' AS cust_marital_status,
50000 AS cust_credit_limit) = 1
In the above example procedure, the schema for the customer historical information is hard-coded. The customer information is stored in the customer table and the following columns are used for scoring a model: cust_gender, cust_year_of_birth, cust_marital_status, cust_credit_limit. Usually, this would not be a problem as many applications work against a fixed schema. Also, in this example, there is no call data passed to the procedure. This type of information can be easily added by either passing it directly as arguments to the procedure or through a different session table that is accessed inside the procedure.
A typical call to score_multimodel would be something like this:
BEGINwhere 1001 is the customer ID, modelmd_tab is the name of the model metadata table, scoretab is the temporary session table, the product filtering condition prod_type = 'credit-card' restricts the recommendations to credit-card products, and the model filtering only allows scoring of cross-sell models for the NE region. A typical output for the procedure would be:
score_multimodel(1001, 'modelmd_tab', 'scoretab',
'prod_type = ''credit-card''',
'model_type = ''cross-sell'' AND region = ''NE''');
END;
prod_id probThe client application would, in general, rank the results by probability and take the top N probabilities. For example, for N=10 we would have:
------- --------
100 0.6
130 0.4
90 0.8
SELECT A.*The next post in this series gives performance numbers for the system. The full series is Part 1, Part 2, and Part 3.
FROM (SELECT prod_id, prob FROM scoretab ORDER BY prob DESC) A
WHERE rownum < 11
Readings: Business intelligence, Data mining, Oracle analytics
Labels: Model Management, Real-Time



