Real-Time Scoring & Model Management 3 - Performance
This is Part 3 in a series on large-scale real-time scoring and model management - The full series is Part 1, Part 2, and Part 3.
Performance
How does the framework proposed in Part 2 of this series perform? Can it scale to large number of models and multiple simultaneous requests? To evaluate the performance of the implementation described in Part 2 I built 100 models using the same set of inputs. For each model I inserted the relevant metadata into modelmd_tab. I then invoked the score_multimodel stored procedure (Part 2) with different WHERE clause arguments so that a different set of models would be selected each time. The number of selected models ranged from 20 to 100. Figure 3 shows the time required for scoring a single row as a function of the number of models. The numbers are for a single 3 GHz CPU Linux box with 2 G of RAM. As indicated in the graph, the proposed architecture achieves real-time (below 1 second) performance. In fact, extrapolating the trend in the graph, it would take about 0.54 seconds to score one thousand models. Actual performance for different systems is impacted by the type of model and the number of attributes used for scoring. Nevertheless, the numbers are representative for an untuned database running on a single CPU box.
Besides the good performance with the number of models, the system also scales well with the number of concurrent users. The architecture can leverage multiple processors and RAC. The cursor sharing feature described in Part 2 also keeps the memory requirements to a minimum while the database caching mechanisms will make good use of available memory. Because we score each model independently, it is also possible for the application to assign groups of models to different servers and increase cache re-use.
It is important to note that the numbers in Figure 3 should not be used as a baseline to estimate the performance of scoring multiple records with a single model in Oracle Data Mining. In this type of task, Oracle Data Mining can score millions of records in a couple of seconds (link).
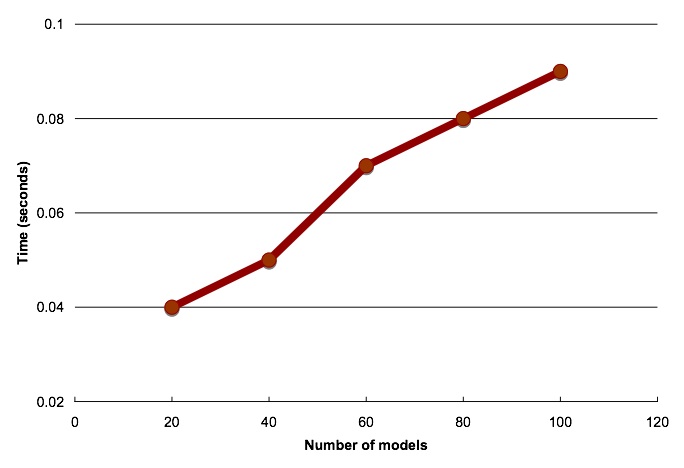
Figure 3: Time for sequentially scoring a single row with multiple models.
I started this series trying to answer the question: Can we implement a large-scale real-time scoring engine, coupled with model management, using the technologies available in the 10gR2 Oracle Database? The answer is Yes. The technologies available in the 10gR2 Oracle Database provide a flexible framework for the implementation of large-scale real-time scoring applications. As shown in the example described above, it is possible to support:
- Large number of models
- Large number of concurrent calls
Readings: Business intelligence, Data mining, Oracle analytics
Labels: Model Management, Real-Time




I think that business rules compliment Data Mining quite well in general and in this scenario specifically. The key thing for the scenario in the post is performance. The rule engine needs to be performant and scale well. One way of combining data mining and rules engine is to use the rule engine as a filter. For the example in the post, it could either select a subset of products to score with DM or the set of filtering conditions to apply at the DM scoring module.
As you pointed out, DM and rules engine can be used to create a powerful solution for applications such as compliance. Many of the requirements in these applications can be defined in terms of business rules. On the other hand, DM can pick up subtle or non-trivial patterns that can be overlooked by business rules.
I think that this type of system could be placed as part of a Decision Service in BPEL. Again the main issue would be performance given the potentially large number of models to score.
Posted by Marcos |
4/05/2006 05:32:00 PM
Marcos |
4/05/2006 05:32:00 PM
The score_multimodel procedure takes as inputs the customer ID, for retrieval of historical data, the model metadata name, the temporary session table name, for persisting results, a WHERE clause for product filtering, and a WHERE clause for model filtering. The procedure scores all models associated with the products filtered by the WHERE clauses. Models are scored one at a time and iakoubtchik results persisted to the temporary session table. Scoring each model separately and using binding variables allow for model caching through shared cursors.
WOW!
Posted by Anonymous |
4/07/2006 12:28:00 PM
Anonymous |
4/07/2006 12:28:00 PM